基础理论篇
完整项目案例运行演示
案例驱动:汽车领域知识图谱
实战开发:知识抽取、建模、推理、存储、应用
源码剖析
案例效果:
- 实体识别(通用和领域)、中文分词、词性标注
- 实体查询(关系图)
- 关系查询(关系图)
项目开发环境安装部署
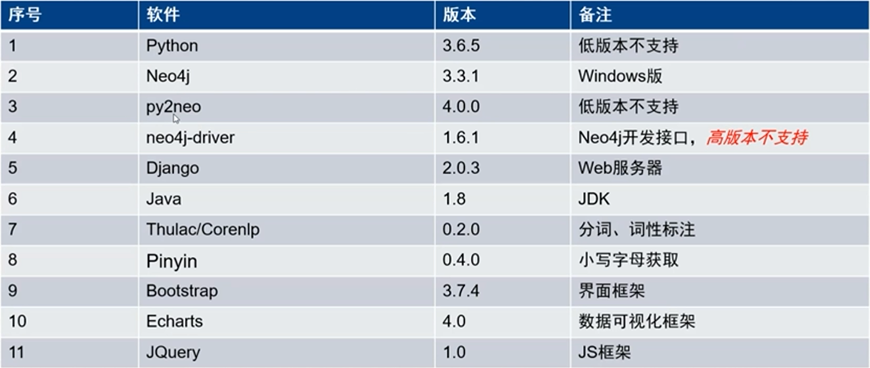
- 建议Djnago和Neo4j运行在同一服务器上
项目业务需求分析
- 基于搜索引擎的商业数据分析
项目总体架构设计
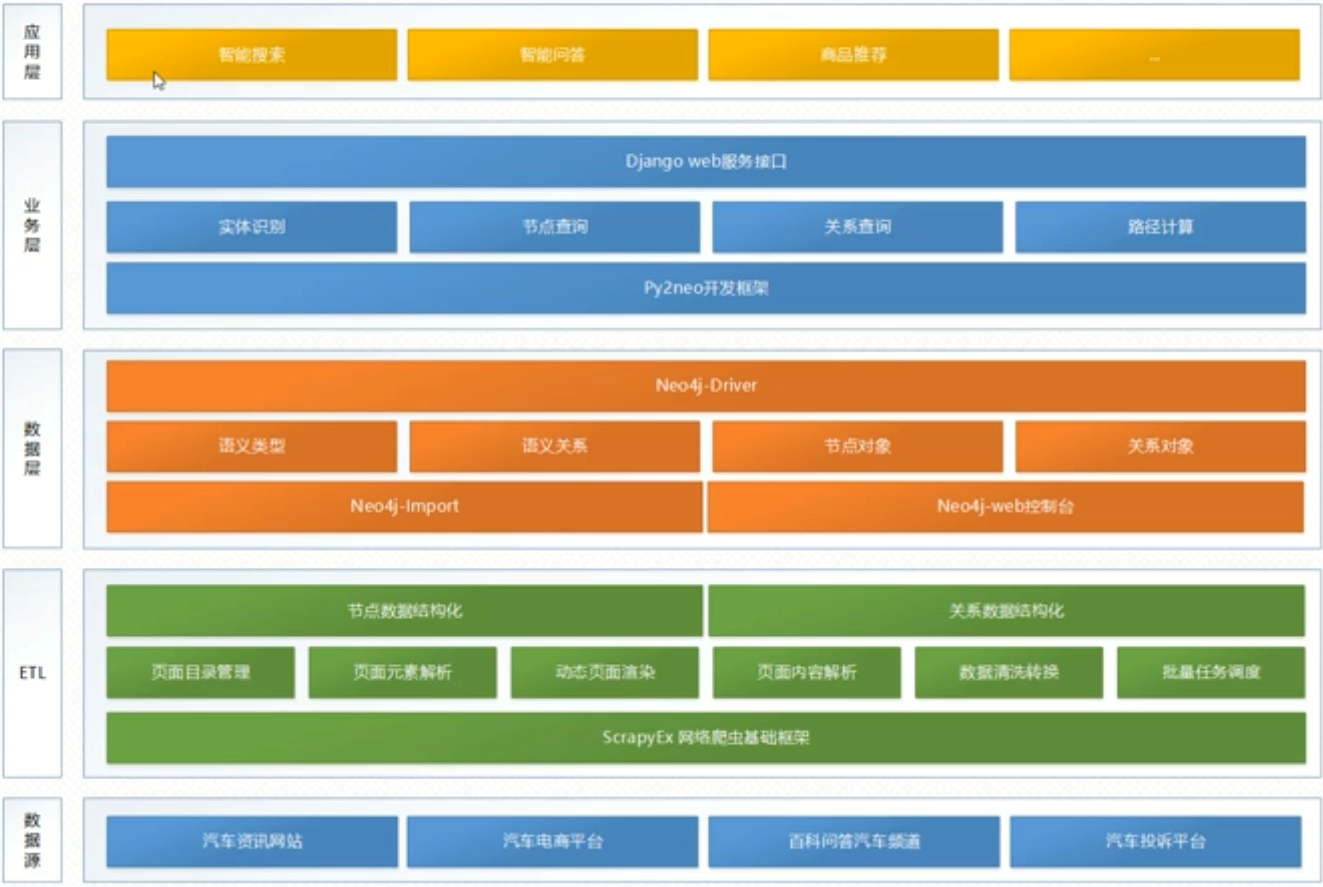
ETL(Extract-Transform-Load, 数据仓库技术):将数据从来源端经过提取(extract)、转换(transform)、加载(load)至目的端
数据源:结构化数据 > 半结构化数据 > 非结构化数据
网络爬虫:Scrapy
模型设计篇
知识图谱模型设计
- 参照法:UMLS(一体化医学语言系统),TCMLS(中医药学语言系统)
- 归纳法:产品生命周期,业务流程拆解
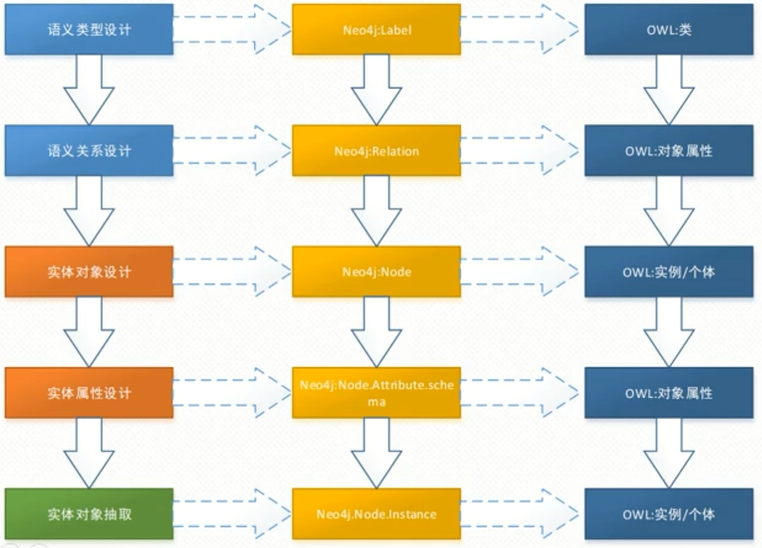
知识图谱语义类型设计
- 高层抽象可复用(参照与对标)
- 现象或过程:被动
- 活动:主动
- 底层明细需适配(归纳法)
知识图谱语义关系设计
方法同上
知识获取篇
- 网络爬虫:动态页面,爬虫与反爬虫
- 数据导入:Neo4j
- 数据资产
开发环境安装部署
- PyCharm
- requests-html
汽车品牌数据获取
- 页面元素分析
1
url = 'https://car.autohome.com.cn/'
汽车车系数据获取
汽车数据批量导入
品牌数据导入
- 将
.csv放入/var/lib/neo4j/import LOAD CSV WITH HEADERS FROM "file:///bank.csv" AS line CREATE (:Bank {name:line.bank, count:line.count})
车系数据导入
- 将
.csv放入/var/lib/neo4j/import LOAD CSV WITH HEADERS FROM "file:///series.csv" AS line CREATE (:Series {name:line.series, count:line.count})
关系数据导入
LOAD CSV WITH HEADERS FROM "file:///series.csv" AS line MATCH (a:Bank{name:line.bank}), (b:Series {name:line.series}) CREATE (a)-[:Subtype]->(b)
创建索引
CREATE CONSTRAINT ON (b:Bank) ASSERT b.name IS UNIQUE
汽车车型数据获取
汽车配置数据获取
程序设计篇
- Web前端框架:django
- 实体关系查询,命名实体查询
- 图数据可视化:Echarts
web前端框架设计
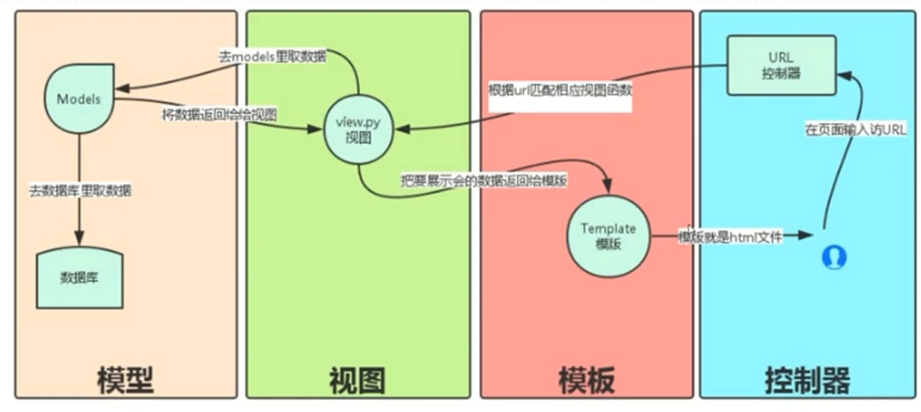
1
2
3urls.py -> *view.py -> templates
python manage.py runserver 0:8000
通用领域命名实体识别
- 三大类:实体类、时间类、数字类
- 七小类:人名、机构名、地名、时间、日期、货币、百分比
基于词典的方法
- 词性标注
- THULAC:一个高效的中文词法分析工具包
1
2
3
4
5n/名词 np/人名 ns/地名 ni/机构名 nz/其它专名
m/数词 q/量词 mq/数量词 t/时间词 f/方位词 s/处所词
v/动词 a/形容词 d/副词 h/前接成分 k/后接成分 i/习语
j/简称 r/代词 c/连词 p/介词 u/助词 y/语气助词
e/叹词 o/拟声词 g/语素 w/标点 x/其它
开源框架CoreNLP
- java
- 基于CRF
/O表示非实体
1 | java -mx600m -cp standford-ner-3.9.1.jar edu.stanford.nlp.ie.NERClassifierCombiner -ner.model classifiers/chinese.kbp.distsim.crf.ser.gz -inputEncoding gb18030 -textFile test.txt |
垂直领域命名实体识别
汽车领域命名实体词典设计和应用(生产环境)
实体查询程序设计
- Neo4j开发驱动
- Py2neo开发框架
run()data()neo4j_models.py
关系查询程序设计
知识图谱数据可视化
- 可视化方案:D3和Echarts
- Echarts
知识图谱应用
推荐系统基本原理和实现机制
推荐系统类型
| 类型 | 算法 | 优势 | 劣势 | 案例 |
|---|---|---|---|---|
| 基于交易历史 | 协同过滤 | 准确性高 | 冷启动 | 商品推荐(啤酒与尿布) |
| 基于行为轨迹 | 协同过滤 | 数据密集 | 准确性低 | 内容推荐 |
| 基于知识图谱 | 相似计算 | 冷热无关 | 知识建模 | 商品推荐 |
知识图谱与推荐系统融合的模式
融合方式
| 方式 | 算法 | 优势 | 案例 | |
|---|---|---|---|---|
| 基于实体属性 | 实体相似 | 线索拓展 | 同一价位 | |
| 基于实体关系 | 实体相关 | 线索拓展 | 同一品牌 | |
| 基于特征向量 | 水波算法 | 线索拓展 | RippleNet | 依次训练、联合训练、交替训练 |
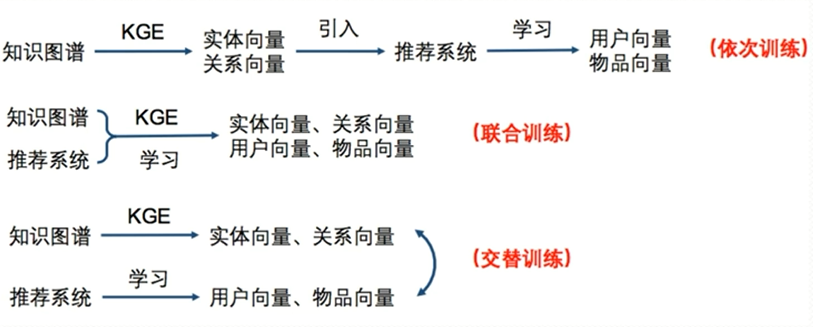
基于KGE的开源推荐系统框架
RippleNet基于KGE的联合训练推荐框架工作原理和实现机制
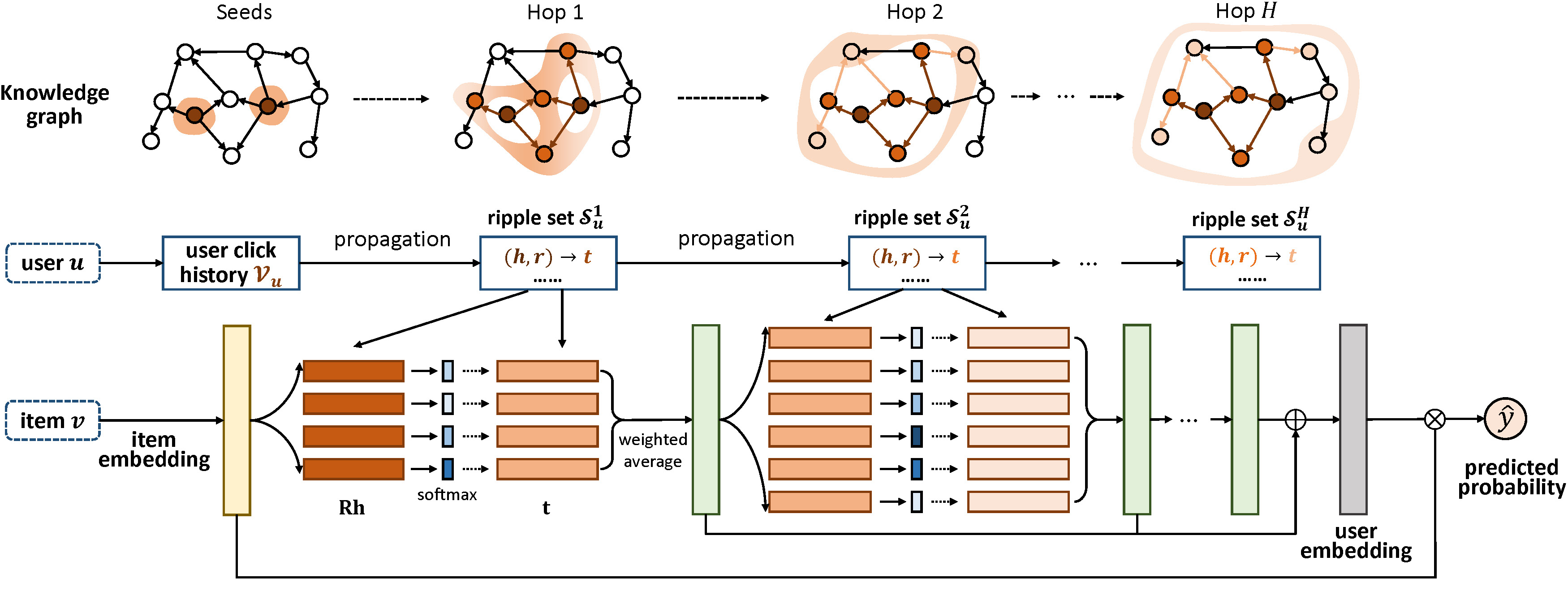
- 绿色条状为输出,最后形成用户向量,并与物品向量计算相似度。
Hop节点向出度方向跳跃一次,形成Ripple集合。- 对于给定的用户
u和物品v,我们将历史相关实体集合V中的所有实体进行相似度计算,并利用计算得到的权重值对V中实体在知识图谱中对应的尾节点进行加权求和。求和得到的结果可以视为v在u的一跳相关实体中的一个响应。该过程可以重复在u的二跳、三跳相关实体中进行,如此v在知识图谱上便以V为中心逐层向外扩散。 RippleNet中没有对用户直接使用向量进行刻画,而是用用户点击过的物品向量集合作为其特征。
RippleNet开源框架源码剖析
- tensorflow